Racing Towards the Future: How AI is Transforming Scientific Inquiry
Fernando Martel García, Ph.D.
2025.01.22
I recently bought a second hand copy of A Handbook of Small Data
Sets, a lovely little
book packed with 510 data sets. Many are so small they can be printed on
half a page, as shown below:
As I was lounging on my sofa, flipping through the book, I had the idea
to snap a picture of the above dataset with my Android phone and analyze
it with ChatGPT 4o. I wanted to experience an end-to-end pass at data
analysis with ChatGPT—from data extraction, to visualization, inference,
estimation, and decision making. All from the comfort of my sofa, using
only my phone. In doing so I wanted to learn about its capabilities, and
get a glimpse at what AI might imply for the future of scientific work.
Below is a somewhat sanitized version of that end-to-end interaction,
followed by my reflections as a scientist about this process.
Because my focus is the impact of AI on the scientific workflows, I
tried to keep the prompts simple and open ended—to see what ChatGPT
does. After all, great research assistants are often ones who don’t need
careful supervision and instruction. I then took whatever it did at face
value and moved on. I will come back to notions of correctness in the
discussion section.
Extracting the Data
I opened the ChatGPT Android app, attached the above photo, and issued
the prompt:
Extract the text and data table from the image
Explain what the data are about
Below is a screenshot of ChatGPT’s response:
Screenshot from ChatGPT’s Windows app
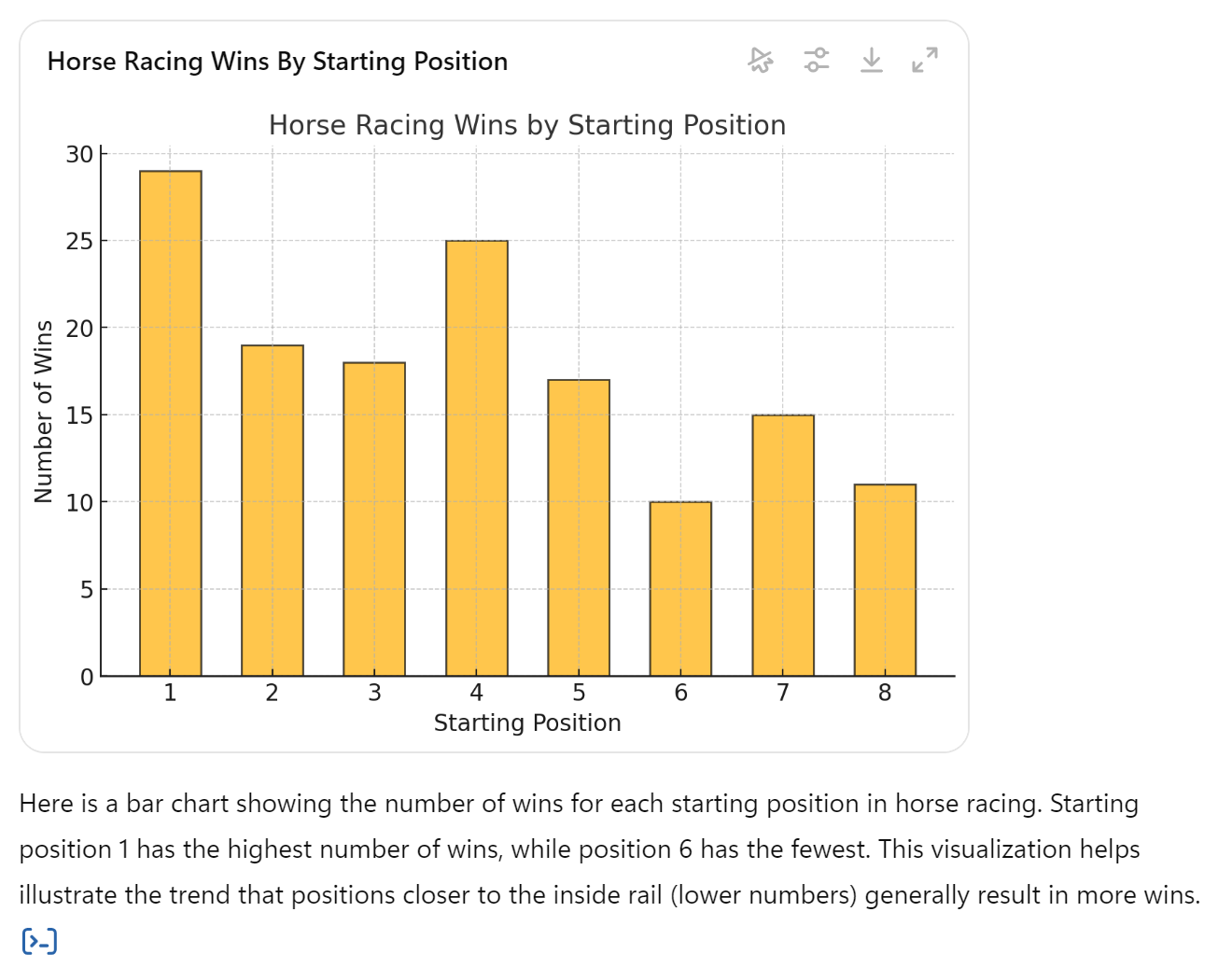
Visualizing the data
Plot the data
Screenshot from ChatGPT’s Windows app
Hypothesis Testing
Next I prompted:
Formally state the null and alternative hypothesis
ChatGPT replied:
Screenshot from ChatGPT’s Windows app
I was expecting a more formal math formulation like:
$$
\begin{align*}
H_0: & [p_1 = \ldots = p_8 = \frac{1}{8}], \\
H_{a1}: & [p_i \neq \frac{1}{8} \text{ for at least one } i \in \{1, \ldots, 8\}].
\end{align*}
$$
Lacking a clear math formulation the alternative hypothesis is
ambiguous. If we have reason to believe starting position 1 is more
likely to be advantageous than 2, which may be more advantageous than 3,
and so on we could have written the ordered alternative hypothesis:
$$
H_{a2}: [p_1 \geq p_2 \geq \ldots \geq p_8 \text{ at least one strict inequality}].
$$
In general, adding more structure to the alternative hypothesis may
increase the probability of detecting a true difference if the assumed
structure is correct. However, as Charles
Manski would point out,
by adding more assumptions it also makes the analysis less credible. As
usual, different scientists will have different beliefs and preferences.
Disagreements will happen.
Next, I prompted ChatGPT to test the null against the alternative
hypothesis:
Test the null against the alternative
To which it replied:
Screenshot from ChatGPT’s Windows app
Basically, the Chi-square test statistic compares observed wins (e.g. 29
wins in position 1) against the expected 18 wins if all starting
positions are equally likely to win (e.g. 144 wins / 8 starting
positions = 18 wins per starting position). Larger differences are less
compatible with the null. In this application the differences are large
enough to reject the null. However, I am still unclear what alternative
hypothesis ChatGPT has in mind. Lets ask it:
I am not exactly sure what is the exact alternative hypothesis. Is it
that position 1 is more likely to win, or that at least one position,
to be determined, is more likely to win. Put differently, we know from
the chi-squared goodness of fit test that the probability of winning
is not 1/8 across all starting positions, but we don’t know which one
is better or worse.
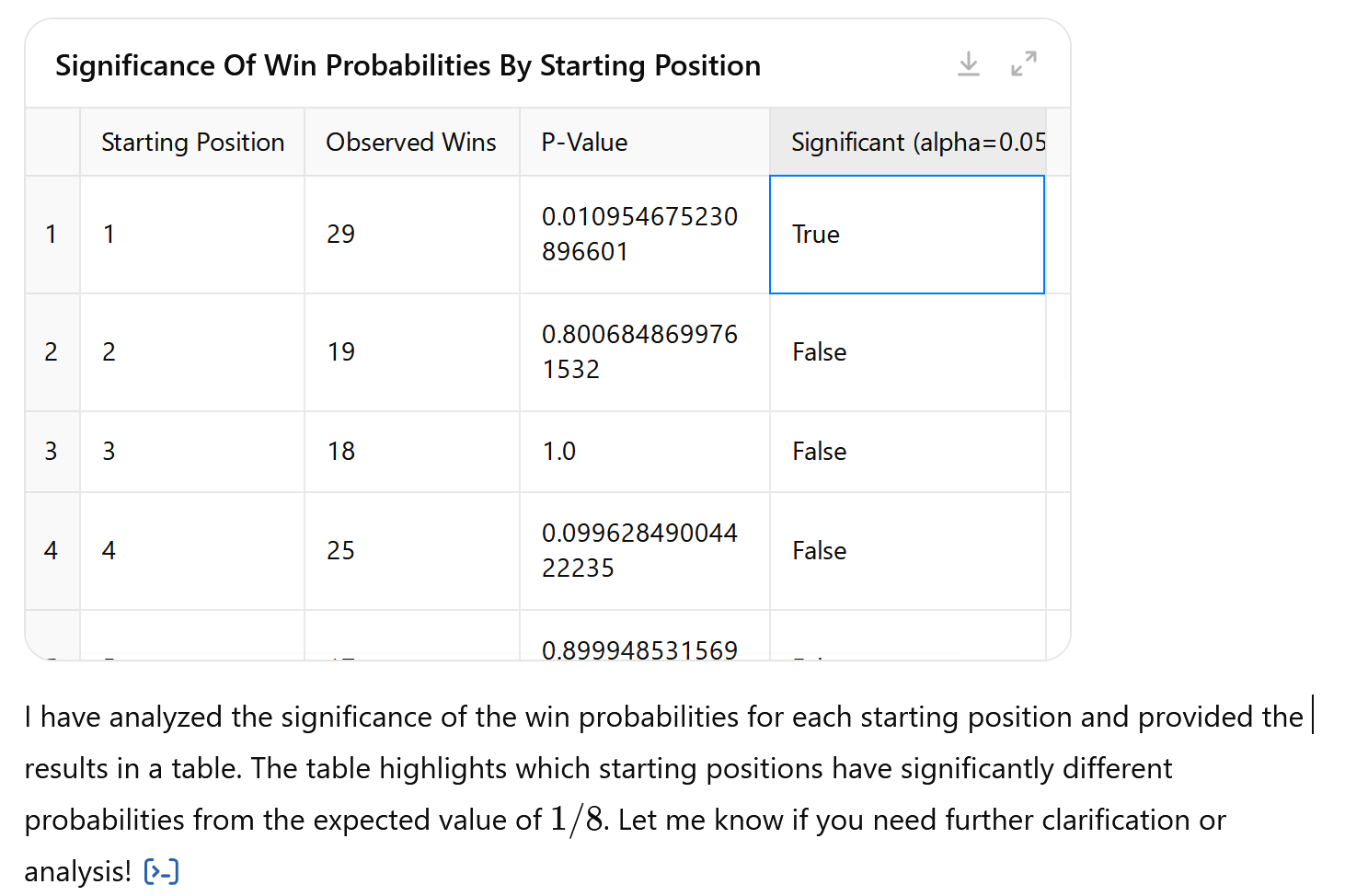
Tell me which starting positions have win probabilities significantly
different from 1/8
Here is the reply:
Screenshot from ChatGPT’s Windows app
It concludes that the proportion of wins in starting positions 1 and 6
(not shown) are significantly different from 1/8.
I tried this last step 3 or 4 times and each time I got a different
analytical approach. Here it using the binomial test with no correction
for multiple hypothesis testing. At other times it used the chi square
test, the Z-test, and the binomial test with Bonferroni correction for
multiple hypothesis testing (in which case no starting position is
significantly different from 1/8).
I would expect four different scientist to come up with four different
answers but I am surprised if the same scientist comes up with 4
different answers in the same day.
Estimation
Taking ChatGPT’s analysis at face value we have learned that the
proportion of wins in positions 1 and 6 are statistically different from
he others. But how much different are they? And are they better or
worse? Again, I asked ChatGPT:
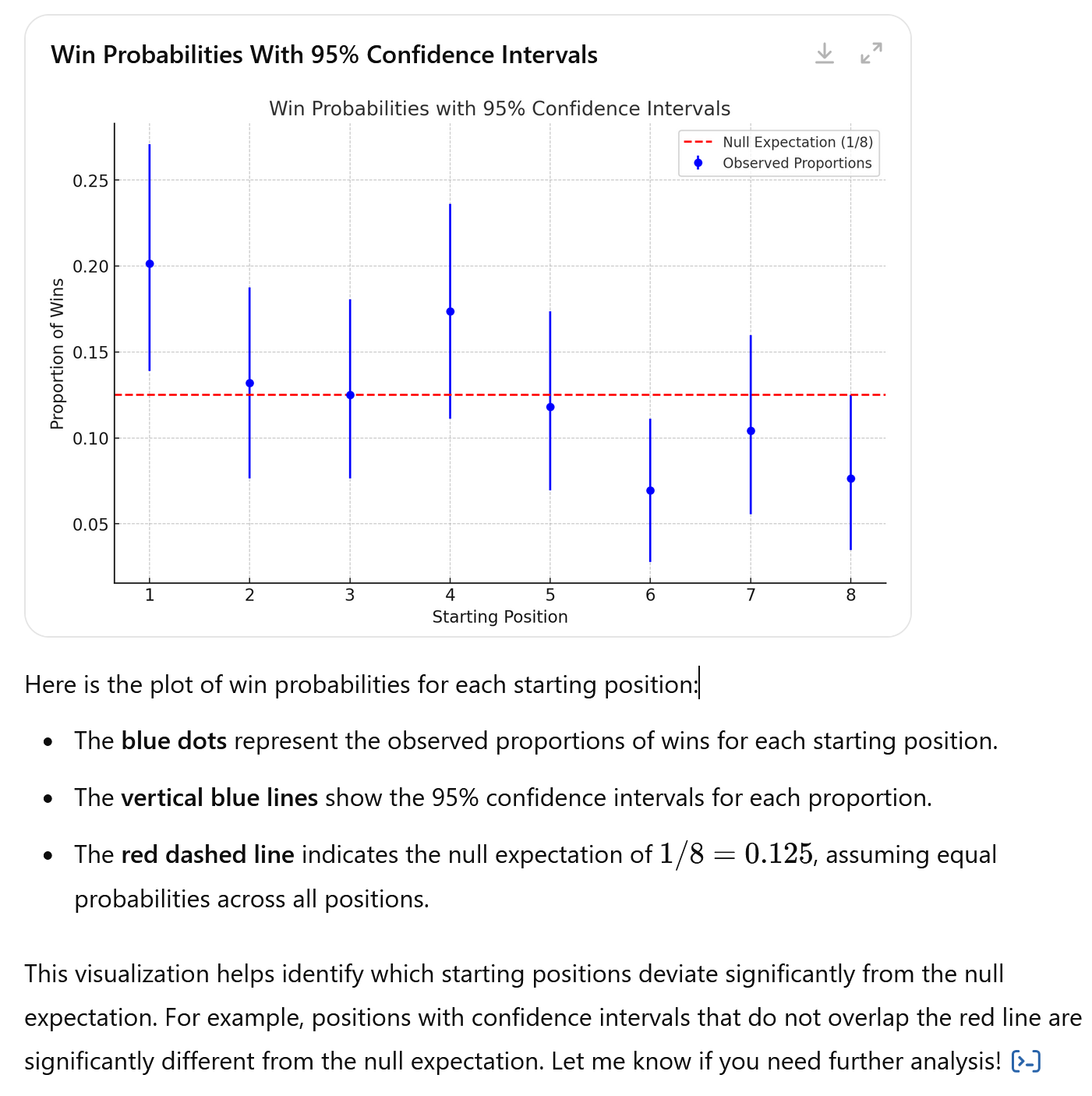
Can you plot the point estimates, the 95% confidence interval, and the
null expectation
Here is the reply:
Screenshot from ChatGPT’s Windows app
This is a very nice chart created in seconds. ChatGPT creates this by
writing and running python code in a cloud playground.
(I said I would not comment on the correctness of the analysis but note
one should be extra careful in picking the correct standard
errors
so the hypothesis tests and the estimates are logically coherent. Also,
some scientist would have started and ended their analysis with the
estimation step. Some would have done OLS straight away. There is
reasonable disagreement about all of this.)
Decision
Often, the point of an analysis like this is to inform some decision to
improve some outcome. For example, if the public perceives the racing
track is unfair, it may damage the track’s reputation, leading to
decreased attendance and revenue. At the same time, taking measures to
adjust starting positions when, in fact, there are no differences in the
proportion of wins is costly. Indeed, it may introduce a problem where
previously there was none.
I asked ChatGPT what to do:
The owner of the horse racing track wants to know if the starting
positions should be adjusted in some way to ensure the proportion of
wins is 1/8 across all starting positions. Based on the analysis thus
far what do you recommend?
The somewhat abridged answer is below:
Screenshot from ChatGPT’s Windows app
As a final test, I started a new chat, attached the picture with the
data and prompted it to do the whole analysis in one shot:
Extract text and data from the picture. Explain the data.
The owner of the horse racing track wants to know if the starting
positions should be adjusted in some way to ensure the proportion of
wins is the same across all starting positions. Analyze the data. What
do you recommend?
It pretty much did all the above in one shot. At this point I put down
my phone and starting thinking about what just happened.
Discussion
First, the experience was awesome! I was exploring a book of tiny
data, got curious about a data set, took a picture with my smartphone,
and conducted an end-to-end analysis using natural language prompts—all
from my sofa. In parallel chats (not reported above), I delved into
various tests, explored their pros and cons, plotted charts, ran
regressions, and more. It was a fantastic way to learn and explore. Take
a screenshot of the data set above and try it yourself!
Second, I can definitely see 60x improvements in productivity in some
discrete tasks but much lower overall. With AI it only takes one
minute to complete some tasks that, previously, may have taken you an
hour. For example:
From
To
Searching books, Google, and notes for the best ways to analyze data, and synthesize the information.
Giving the AI the data, context, and a prompt, and getting a summary of options with pros and cons.
Searching google, Stack Overflow, etc., for coding solutions, copy pasting them, and running them.
Asking the AI to write, run, and debug the code.
Writing an analysis of the statistical results.
Asking the AI to draft it.
Generating ideas for solving a problem.
Asking the AI to generate ideas.
This is a game changer. It enables scientists to operate at a much
higher level of abstraction. For example, as abstraction rises, code
becomes the new log files.
In the case study above, ChatGPT provided links to the code it
generated, but you may find yourself looking at the code less
frequently. AI will handle all errors at that layer. AI will also
disrupt writing, editing, typesetting, idea generation, literature
reviews, synthesis, and many others. Still, these are only a relatively
small share of scientists’ work, so the overall productivity increase is
likely to be less than 60x, at least in the immediate future.
Moreover, it is hard to see how AI will remove [hard binding
constraints
like recruiting patients to a trial, waiting for the effect of an
intervention to manifest itself (e.g. the impact of an education
intervention on labor outcomes may take weeks, months, or years), and so
on. Maybe one day we develop in silico models so good, we no longer
need to experiment in the real world. But if our in silico models are
so good, then why would we need to experiment? And if not, then why
should we trust their answers?
Third, the clash of powerful AI and pernicious research incentives
will result in drastic changes to the way science is taught and
practiced. AI can drastically improve, or worsen, science. It can be
used to adopt better, more laborious, scientific practices—like writing
pre-analysis plans and simulation-based power calculations—or to
manufacture bogus findings at scale.
The impact will depend on the interaction between technology and
incentives. Currently, the incentives are
terrible.
The opportunity cost of wasteful science is about to skyrocket. Change
will happen much faster than most expect.
Fourth, at present I would not trust an AI to do the full analysis,
nor would I act blindly on its recommendations. This is a topic of
another blog post. Suffice it to say that the simple horse racing case
study above hides many tiny steps, options, and consequential decisions.
Which option and path is best for you depends on unknown states of the
world, as well as your preferences, beliefs, and risk tolerance. Here
are some things ChatGPT papered over:
Was the horse’s starting position randomized before each race?
Is the alternative hypothesis ordered or not?
What test statistic, power, level of significance and inferential
method is best fit for the purpose at hand? According to what
criteria (e.g. Pittman efficiency)?
How to approach post hoc multiple hypothesis testing?
What are possible estimators, and specifications for standard
errors? How to choose among them?
What are the relevant states of the world for these decisions, and
their probabilities?
What are the available actions and their payoffs under the various
states of the world?
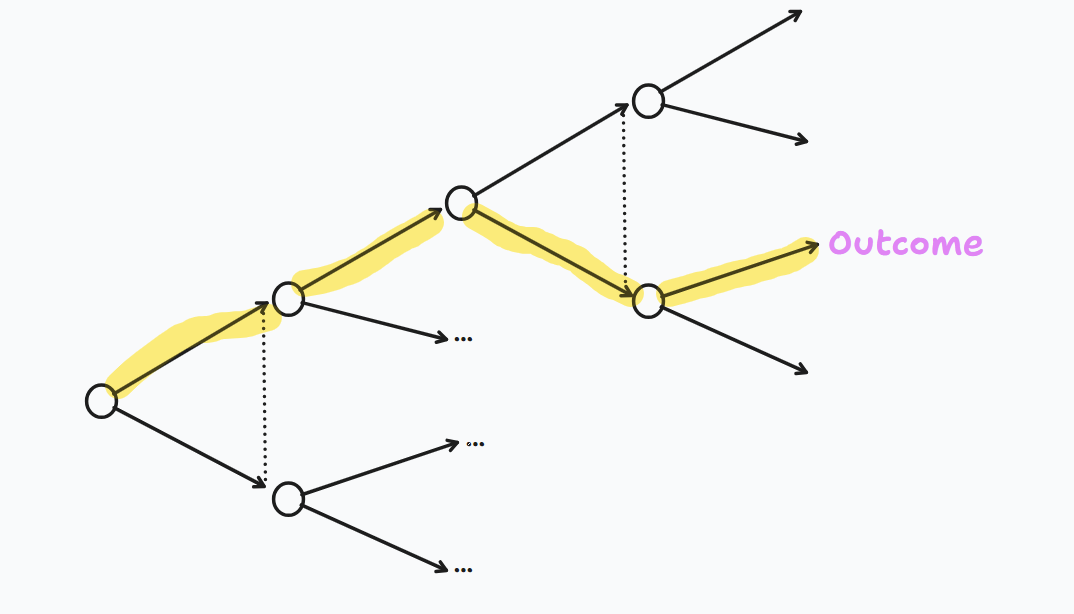
All the above generate a decision tree, or garden of forking
paths.
For now, ChatGPT does not solve the decision tree. It simply predicts
the next step based on its training, prompts, and previous answers. The
final analysis corresponds to a single path like the one highlighted
below. Whether that analysis is fit, or not, for your purpose is for you
to adjudicate, maybe with further prompting to ChatGPT—but you need to
know what to ask!
Illustrative sketch of the garden of forking paths, and ChatGPTs
predicted path in yellow.
You could use prompt engineering, chain of thought, and so on to try to
get it to go down your preferred path, or hope that new reasoning models
like DeepSeek
R1
get better at this.
Taking the results blindly is not without risk. For instance, when
ChatGPT rejected the null hypothesis it concluded: “There is evidence to
suggest that the starting position has a significant effect on a horse’s
chances of winning a race (my emphasis)”. It assumes causation form
association (like much of the published literature).
If the cost of remedial action is high, and experiments are cheap, you
may want to run a few experiments before taking any action. In addition,
ChatGPT’s decisions are stochastic, meaning you may get a different
solution path each time you ask. Reproducibility may require setting a
random seed.
For now, the biggest value scientists add is knowing the right
questions to ask, and working with AI to resolve the decision tree in
line with decision-maker preferences.
I am very excited about this. In my experience most applied scientists
have been so bogged down in the implementation details, that they do not
spend nearly enough time modeling the stakeholder’s decision. Yet,
presumably, the whole research design should work backwards from that
decision. We are about to unlock that at scale.
What an exciting time to be a scientist!
References
Hand, David J, Fergus Daly, K McConway, D Lunn, and Elizabeth Ostrowski.
1993. A Handbook of Small Data Sets. cRc Press.
https://doi.org/10.1201/9780429246579.↩